




在本公司的路由器中实现了多个IP路由动态协议,它们将在本文中各个协议的说明中分别予以介绍。
IP路由协议一般分为两类:内部网关路由协议(IGP)和外部网关路由协议(EGP)。本公司路由器支持RIP、OSPF、BGP和BEIGRP。您可以根据您的需要分别配置RIP、OSPF、BGP和BEIGRP。在我们的路由器上,支持同时配置多个路由协议的进程,包括任意多个的OSPF进程(如果内存能够分配),一个BGP进程,任意多个RIP进程和任意多个的BEIGRP进程。您可以使用redistribute将其它路由协议的路由重新发布到当前的路由进程的数据库中,以此来将多个协议进程的路由联系起来。
为了配置IP动态路由协议,首先必须配置创建相应的进程,并且将相应的网络端口与一定的动态路由进程相联系起来,指定路由进程在那些端口上启动。为此,你可能需要在相应的配置命令文档中查看相关的配置步骤。
选择路由协议,这是一个复杂的过程。在选择路由协议的时候,你必须考虑如下的因素:
• 网络的大小以及复杂度
• 是否需要支持可变长网络
• 网络流量
• 安全的要求
• 可靠性的要求
• 策略
• 其它
在这里,我们并不深入的介绍这个问题,只是提醒用户注意,您所选择的路由协议必须要能够满足您网络的情况,适应您的需求。
内部网关路由协议是用来在一个自治系统中的网络目标。所有的IP内部网关路由协议在启动的同时必须将其与一定的网络相联系起来(比如配置network)。每个路由进程都监听网络上的来自其它路由器的更新报文,同时在网络上广播它自己的路由信息。本公司路由器支持的内部网关路由协议有:
• RIP
• OSPF
• BEIGRP
外部网关路由协议是用来在不同自治系统之间交换路由信息。一般要求配置相应的用来交换路由的邻居、公布为可到达的网络以及本地的自治系统号。本公司路由器支持的外部网关路由协议有BGP。
VPN的关键之一是保持安全,分隔数据;它必须防止不属于同一VPN的站点之间的通信。为了让PE路由器上能区分是哪个本地接口上送来的VPN用户路由,在PE路由器上创建了大量的虚拟路由器,每个虚拟路由器都有各自的路由表和转发表,这些路由表和转发表统称为VRF(VPN Routing and Forwarding instances)。一个VRF包含了同一个站点相关的路由表、转发表、接口(子接口)、路由实例以及路由策略等。在PE设备上,属于同一个VPN的物理端口或逻辑端口对应一个VRF。
如果想配置静态路由,需要完成下面的任务。
• 创建VRF表
• 将接口与VRF相关联
• 配置VRF的目标VPN扩展属性
• 配置VRF的描述说明
• 配置VRF静态路由
• 监视VRF
• 维护VRF
• VRF配置举例
要创建VPN路由和转发表,在全局配置模式下按以下步骤进行:
|
命令 |
目的 |
|
PE_config#ip vrf ce |
进入VRF配置模式,定义VRF表。 |
|
PE_config_vrf_ce#rd ASN:nn or IP-address:nn |
指定VRF的路由标记,创建VRF路由和转发表 |
|
PE_config_vrf_ce#route-target [export | import | both ] ASN:nn or IP-address:nn |
创建VRF的输入和输出目标VPN扩展属性 |
将接口与VRF相关联,按以下步骤进行:
|
命令 |
目的 |
|
PE_config#interface vlan 1 |
进入接口配置模式。 |
|
PE_config_v1#ip vrf forwarding vrf-name |
将接口与VRF相关联。 |
|
PE_config_v1#ip address ip-address subnet-mask |
配置接口IP地址。 |
配置VRF的目标VPN扩展属性,按以下步骤进行:
|
命令 |
目的 |
|
PE_config#ip vrf ce |
进入VRF配置模式。 |
|
PE_config_vrf_ce#rd ASN:nn or IP-address:nn |
配置VRF路由标记,创建VRF表。 |
|
PE_config_vrf_ce#route-target [export | import | both ]ASN:nn or IP-address:nn |
配置VRF的输入和输出目标VPN扩展属性。 |
|
PE_config_vrf_ce#import map WORD |
配置加入VRF路由表中的路由的route-map过滤。 |
|
PE_config_vrf_ce#export map WORD |
将符合route-map条件的目标VPN扩展属性加入到VRF的输出目标VPN扩展属性中。 |
在将本地路由发布给其它PE路由器之前,入口PE将为从直连站点学习到的每条路由附加一个路由目标属性。附加到路由上的目标值是基于在输出目标扩展属性中配置的VRF的值。
在将由其它PE发布的远端路由安装在本地VRF前,出口PE路由器上的每个VRF都将配置一个输入目标扩展属性。PE路由器只有在VPN-IPv4路由中承载的路由目标属性与某一PE路由器上的VRF输入目标相匹配时,才会将该路由安装到某一VRF中。
配置VRF的描述说明,按以下步骤进行:
|
命令 |
目的 |
|
PE_config#ip vrf ce |
进入VRF配置模式。 |
|
PE_config_vrf_ce#rd ASN:nn or IP-address:nn |
配置VRF路由标记,创建VRF表。 |
|
PE_config_vrf_ce# description LINE |
配置VRF的描述说明。 |
配置VRF静态路由,按以下步骤进行:
|
命令 |
目的 |
|
PE_config#ip vrf ce |
进入VRF配置模式。 |
|
PE_config_vrf_ce#rd ASN:nn or IP-address:nn |
配置VRF路由标记,创建VRF表。 |
|
PE_config_vrf_ce#exit |
退出VRF配置模式。 |
|
PE_config#ip route [vrf vrf-name] dest mask { type num | nexthop } [distance] |
配置VRF静态路由。 |
监视VRF,可以显示VRF的统计信息。要监视,按以下步骤进行:
|
命令 |
目的 |
|
PE#show ip vrf |
显示VRF及所关联的端口信息。 |
|
PE#show ip vrf [{brief | detail | interfaces}] vrf-name |
显示VRF配置信息及相关联的端口信息。 |
|
PE#show ip route vrf vrf-name[A.B.C.D | all | beigrp | bgp | ospf | rip | connect | static | summary ] |
显示VRF路由表中路由信息。 |
维护VRF,跟踪主路由表和VRF路由表路由的变化及VRF配置信息的变化,在管理态下,按以下步骤进行:
|
命令 |
目的 |
|
PE#debug ip routing |
跟踪主路由表中路由的添加、删除、改变等路由的变化情况。 |
|
PE #debug ip routing message |
跟踪VRF接收和发送的信息。 |
|
PE #debug ip routing vrf vrf-name |
跟踪指定VRF路由表中路由的添加、删除、改变等路由的变化情况。 |

路由器的配置如下:
路由器CE:
interface loopback 0
ip address 22.1.1.1 255.255.255.0
!
interface vlan 1
ip address 170.168.20.152 255.255.255.0
!
router ospf 1
network 170.168.20.0 255.255.255.0 area 0
network 22.1.1.0 255.255.255.0 area 0
!
路由器PE1:
ip vrf pe1
rd 1:1
route-target 1:1
!
interface vlan 1
ip vrf forwarding pe1
ip address 170.168.20.153 255.255.255.0
!
interface vlan 2
ip address 176.168.20.152 255.255.255.0
!
router ospf 1 vrf pe1
network 170.168.20.0 255.255.255.0 area 0
!
router bgp 1
neighbor 176.168.20.154 remote-as 2
address-family vpnv4
neighbor 176.168.20.154 activate
exit-address-family
address-family ipv4 vrf pe1
no synchronization
redistribute ospf 1
exit-address-family
路由器PE2:
ip vrf pe2
rd 1:1
route-target 1:1
!
interface loopback 0
ip vrf forwarding pe2
ip address 44.1.1.1 255.255.255.0
!
interface vlan 2
ip address 176.168.20.154 255.255.255.0
!
router bgp 2
neighbor 176.168.20.153 remote-as 1
address-family vpnv4
neighbor 176.168.20.153 activate
exit-address-family
address-family ipv4 vrf pe2
no synchronization
redistribute connected
exit-address-family
静态路由是一种特殊的路由,由管理员手工配置。在组网结构比较简单的网络中,只需配置静态路由就可以实现网络互通。恰当地设置和使用静态路由可以改善网络的性能,并可为重要的网络应用保证带宽。
静态路由的缺点在于:不能自动适应网络拓扑结构的变化,当网络发生故障或者拓扑发生变化后,可能会出现路由不可达,导致网络中断,此时必须由网络管理员手工修改静态路由的配置。
默认路由是在路由器找不到匹配的路由表项时才使用的路由:
如果报文的目的地址不能与路由表中的任何表项相匹配,那么该报文将选择默认路由;
如果没有默认路由且报文的目的地不在路由表中,那么该报文将被丢弃。
默认路由可以通过静态路由配置,以到网络0.0.0.0/0的形式在路由表中出现。
如果想配置静态路由,需要完成下面的任务。
• 配置相关接口的物理参数
• 配置相关接口的链路层属性
• 配置相关接口的IP 地址
要配置静态路由,需要进入全局配置模式,按以下步骤进行:
|
命令 |
目的 |
|
ip route A.B.C.C mask {next-hop | interface} [distance] [tag tag] [global] [description][vrf] |
配置静态路由。 |
指定到网段10.0.0.0/8的报文的下一跳为1.1.1.2,配置如下:
ip route 10.0.0.0 255.0.0.0 1.1.1.2
路由信息协议RIP是一个相对过时但仍然普遍使用的内部网关协议(IGP),主要应用于规模较小的同质型网络。RIP是一个经典的距离向量路由协议,出现在RFC 1058中。
RIP通过用户数据报协议UDP数据分组的广播来交换路由信息。在路由器中,每30秒钟发送一次路由信息的更新。如果一台路由器在180秒内没有接收到来自相邻路由器的更新,便把路由表中来自该路由器的路由标记为“不可用的”。如果接下去的120秒内仍然没有接收到更新,便把这些路由从路由表中删除。
RIP使用跳跃计数(hop count)来作为衡量不同路由的权值。这个跳跃计数是指一个分组从信源到达信宿所经过的路由器的数目。直接相连网络的路由权值为0,不可到达网络的路由权值为16。由于RIP使用的路由权值范围较小,所以对大规模的网络就显得不大适合。
如果路由器有一条缺省路由,RIP就宣告通向伪网络0.0.0.0的路由。实际上,网络0.0.0.0并不存在,它只是用来在RIP中实现缺省路由的功能。如果RIP学习到了一条缺省路由,或者路由器中设置了默认网关并配置了缺省权值,路由器都将宣告这个缺省的网络。
RIP向指定网络中的接口发送路由更新。如果一个接口所在的网络没有被指定,该网络不会在任何RIP更新中宣告。
本公司路由器的RIP-2支持明文和MD5及动态认证、路由汇总、无分类域间路由(CIDR)和变长子网掩码(VLSM)。
如果想配置RIP,必须完成下面的任务。你首先要建立RIP实例,其余的任务则是可选的。
• 启动RIP实例
• 允许RIP路由更新分组的单目广播
• 对路由权值应用偏移量
• 调整计时器
• 指定RIP版本号
• 激活RIP认证
• 激活接口的“聋”“哑”状态
• 禁止路由汇总
• 禁止信源IP地址认证
• 激活或禁止水平分割
• RIP配置举例
• 水平分割举例
要激活RIP实例,进入全局配置模式,按以下步骤进行:
|
命令 |
目的 |
|
router rip process-id [vrf vrf-name] |
建立RIP实例,进入路由器RIP实例配置模式。 |
启动RIP实例后,只有接口关联到实例下才能生成RIP的直连网段,以及用这些接口和邻居交换路由信息。实例要关联接口,在接口的配置态,按以下步骤进行:
|
命令 |
目的 |
|
ip rip process-id enable |
将接口关联到process-id实例中。 |
若要使接口成为RIP的激活接口(生成接口的直连路由,接口能够收发RIP协议报文),需要满足:接口关联到RIP实例,接口上有合法的ip地址,接口的状态up。
另外,当在一个接口中enable一个RIP实例的时候,若该接口被指定了vrf,而实例的vrf和接口上的vrf不一致,该接口不能够成为RIP的激活接口,直到修订了接口的vrf。
当一个接口关联了一个尚未创建的RIP实例,将会以接口上的vrf(若被指定了vrf)和enable的process-id创建RIP实例。
每个接口只能属于一个RIP实例。
RIP通常是一个广播型协议,如果要使RIP路由更新能够到达非广播型网络,你必须对交换机进行配置以允许路由信息的交换。要达到这样的目的,在路由配置模式中使用如下命令:
|
命令 |
目的 |
|
neighbor ip-address |
定义一个邻居路由器,与之交互路由信息。 |
另外,如果你想控制哪些接口可以用来交换路由信息,可以使用命令ip rip passive指定在某个(某些)接口上禁止路由更新的发送。如果参考在“配置IP路由中与协议无关的命令”一章中的“过滤路由信息”中关于路由过滤的讨论。
偏移量列表是用来对那些由RIP学习到的入站和出站路由增加一个偏移量。这就提供了一个本地的机制来增加路由权值。另外,你还可以使用访问列表或接口来限制偏移量列表。要增加路由权值,在路由配置模式中使用如下命令:
|
命令 |
目的 |
|
offset {[interface-type number]|* }{in|out} access-list-name offset |
对路由权值增加一个偏移量。 |
路由协议使用几个计时器来判断发送路由更新的频率、多长时间内路由变为无效以及其它参数。你可以调整这些计时器使路由协议的性能更适合网络互联的需要。
也有可能调整路由协议来加速各种IP路由算法的收敛时间,做到向冗余路由器的快速备份,以达到在需要快速恢复(quick recovery)的场合中向终端用户保证最小的崩溃时间。要调整计时器,在路由配置模式中使用如下命令:
|
命令 |
目的 |
|
timers holddown value |
经过多长时间(单位:秒)从路由表中删除某一条路由。 |
|
timers expire value |
经过多长间隔(单位:秒)路由被宣告为无效。 |
|
timers update value |
发送路由更新的频率(发送更新的间隔,单位:秒)。 |
本公司交换机的RIP-2支持认证、密钥管理、路由汇总、无分类域间路由(CIDR)和变长子网掩码(VLSM)。
缺省情况下(没有配置全局和端口上的version),路由器接收RIP-1和RIP-2的分组,向外发送分组的时候,若端口有peer则依据RIP的自适应规则,(一个端口上若只有一个peer或者有多个peer但peer彼此的version都一致,则按peer的version响应;若同一个端口上有多个peer但peer彼此的version不一致,则依据系统的RIP缺省情况处理),若没有peer则发送缺省的RIP-2的分组。通过配置,可以使路由器仅发送和接收RIP-1的分组,或者仅发送和接收RIP-2的分组。要达到这样的目的,在路由配置模式中使用如下命令:
|
命令 |
目的 |
|
version {1 | 2} |
配置路由器仅仅发送和接受RIP-1或RIP-2的分组。 |
上述的任务控制RIP的缺省行为。你也可以配置某一特定接口来改变这个缺省行为。要控制接口发送RIP-1分组还是RIP-2分组,以及要控制发送request的时候的分组,在接口配置模式下使用如下命令:
|
命令 |
目的 |
|
ip rip send version 1 |
配置接口仅仅发送RIP-1的分组。 |
|
ip rip send version 2 |
配置接口仅仅发送RIP-2的分组。 |
|
ip rip send version compatibility |
广播发送RIP-2更新报文。 |
|
ip rip v1demand |
在发送request的时候发送RIP-1的分组。 |
|
ip rip v2demand |
在发送request的时候发送RIP-2的分组。 |
同样,要控制接口接收RIP-1分组还是RIP-2分组,在接口配置模式下使用如下命令:
|
命令 |
目的 |
|
ip rip receive version 1 |
配置接口仅仅接受RIP-1的分组。 |
|
ip rip receive version 2 |
配置接口仅仅接受RIP-2的分组。 |
|
ip rip receive version 1 2 |
配置接口可以接受RIP-1和RIP-2的分组。 |
在缺省情况下RIP覆盖的接口是可以发送和接收路由更新的,通过配置可以灵活应用RIP协议,让RIP接口处于只接收不发送或者只发送不接受状态。
要配置接口的聋哑状态,要在接口配置模式下进行:
|
命令 |
目的 |
|
Ip rip passive |
接口不发送rip协议分组。 |
|
ip rip deaf |
接口不接受rip协议分组。 |
RIP-1不支持认证。如果你在发送和接收RIP-2的分组,你可以在接口上激活RIP认证功能。
在RIP激活的接口上,我们支持多种认证模式:明文认证、MD5认证、动态认证(md5和sha1)。每个RIP-2分组中缺省时使用明文认证。
注意:
如果处于安全的目的,不要在RIP分组中使用明文验证,这是因为未经加密的认证密钥发送在每个RIP-2分组中。如果在不涉及安全问题的情况下(例如:要保证配置错误的主机不能参与路由),可以使用明文验证。
要配置RIP明文认证,在接口配置模式下,按如下步骤进行:
|
命令 |
目的 |
|
ip rip authentication simple |
配置接口使用明文认证。 |
|
ip rip password [string] |
配置明文认证密钥。 |
要配置RIP的MD5认证,在接口配置模式下,按如下步骤进行:
|
命令 |
目的 |
|
ip rip authentication md5 |
配置接口使用MD5认证。 |
|
ip rip md5-key [key-ID] md5 [key] |
配置MD5认证密钥和认证ID 。 |
要配置RIP的动态认证,在接口配置模式下,按如下步骤进行:
|
命令 |
目的 |
|
ip rip authentication dynamic |
配置接口使用动态认证(md5和sha1)。 |
|
ip rip dynamic-key [key-ID] { md5 | sha1 } [key] xxxx-xx-xx-xx:xx xx:xx |
配置动态认证密钥和认证ID。 |
RIP认证配置完毕后,建议在接口配置模式下,按如下步骤进行:
|
命令 |
目的 |
|
ip rip authentication commit |
认证通不过时尽快老化对端peer和从对端学到的路由。 |
RIP-2在缺省情况下支持自动路由汇总。在穿越有类别网络边界时汇总RIP-2路由。RIP-1自动路由汇总功能总处于激活状态。
如果有一个分离的子网,就要禁止路由汇总来宣告这个子网。如果路由汇总被禁止,在穿越由类别网络边界时,路由器将传送子网和主机的路由信息。在路由配置模式下,使用下面命令来禁止自动汇总。
|
命令 |
目的 |
|
no auto-summary |
禁止自动汇总。 |
缺省情况下,路由器会对收到的RIP路由更新的可信源IP地址进行验证。如果这个地址非法,将丢弃这个路由更新。
如果你有一台路由器希望接收来自它的更新,但是你并没有在接受端的路由器的接口上关联对应的rip实例,那么就可以禁止这个功能。但在正常情况下,推荐你不要使用这个命令。在路由器配置模式下使用如下命令将禁止对入站路由更新的可信源IP地址进行验证的缺省功能。
在缺省情况下,路由器会对收到的version 1下路由条目的必须为零的字段进行验证。如果相应的字段不能通过零域的合法性检验,该路由条目将被丢弃。如果配置不进行该项验证,将可能导致本地学习到对端发送过来的错误的路由信息
|
命令 |
目的 |
|
no validate-update-source |
禁止对入站RIP路由更新的可信源IP地址的验证。 |
|
no check-zero-domain |
禁止对入站RIP路由更新的必须为零字段的验证。 |
在缺省情况下,RIP路由信息最多允许生成4条等价路由。当从多个邻居学习到某个或某些相同网段的路由信息生成等价路由时,若某个网段的等价路由数大于当前最大等价路由数将不能添加到RIP的database中。
在路由配置模式下使用如下命令对RIP本地路由表中最大等价路由数进行配置:
|
命令 |
目的 |
|
maximum-nexthop number |
配置RIP路由信息最大等价路由数 。 |
|
No maximum-nexthop |
恢复缺省最大等价路由数 。 |
正常情况下,与广播型IP网络相连并使用距离向量路由协议的路由器采用水平分割机制来减小路由环路的可能性。水平分割阻塞路由信息向接收到该路由信息的接口进行宣告。这样做可以优化多个路由器间的通信(尤其是在环路打破的时候)。但是,对于非广播型网络(例如帧中继),情况并非那么理想。此时,你可能要禁止水平分割。
如果一个接口配置了辅助的IP地址并且激活了水平分割,路由更新的信源IP地址可能不包括每一个辅助地址。一条路由更新中的信源IP地址只包括一个网络号(除非水平分割被禁止)。
要激活或禁止水平分割,在接口配置模式下使用如下命令:
|
命令 |
目的 |
|
ip rip split-horizon {simple | poisoned} |
激活水平分割。 |
|
no ip rip split-horizon {simple | poisoned} |
禁止水平分割。 |
在缺省情况下,对于点对点接口,水平分割是激活的;对于点对多点接口,水平分割是禁止的。可选参数simple和poisoned分别表示简单水平分割和带毒性逆转的水平分割。
请参考本章中“水平分割举例”一节中关于使用水平分割的具体例子。
注意:
在一般情况下,推荐你不要改变缺省状态,除非你能肯定你的应用程序需要状态的改变才能正确地宣告路由。记住:如果水平分割在一个串行接口上被禁止(并且与该接口相连的是一个分组交换网),你必须对该网络上任何相关多目广播组中的路由器禁止水平分割。
监视和维护RIP,可以显示网络的统计信息,如:RIP协议参数配置、使用网络、网络通信实时跟踪等。这些信息能帮助你判断网络资源的利用,解决网络问题。能了解网络节点的可达性。
在管理态输入命令,使用下面的命令,可以显示各种路由统计信息。
|
命令 |
目的 |
|
show ip rip |
显示所有RIP实例当前状态。 |
|
Show ip rip process-id |
显示具体某个RIP实例的当前状态 |
|
show ip rip process-id database |
显示某个RIP实例的所有路由。 |
|
show ip rip process-id protocol |
显示某个RIP实例协议相关信息。 |
|
show ip rip process-id summary |
显示RIP路由汇总信息 |
|
show ip rip process-id peer |
显示RIP peer 信息 |
|
Show ip rip process-id interface |
显示某个RIP实例全部的接口及接口状态 |
在管理态输入命令,使用下面的命令,可以跟踪路由协议信息。
|
命令 |
目的 |
|
debug ip rip database |
跟踪RIP路由加入路由表、从路由表中删除路由、路由改变等过程信息。 |
|
debug ip rip packet |
跟踪RIP报文的接收和发送 |
|
Debug ip rip message |
跟着RIP事件,如定时器超时 |
两台85系列交换机,配置如下:
交换机A:
interface vlan1
ip address 192.168.20.81 255.255.255.0
ip rip 1 enable
!
interface loopback 0
ip address 10.1.1.1 255.0.0.0
ip rip 1 enable
!
router rip 1
!
交换机B:
interface vlan1
ip address 192.168.20.82 255.255.255.0
ip rip 1 enable
!
interface loopback 0
ip address 20.1.1.1 255.0.0.0
ip rip 1 enable
!
router rip 1
!
BEIGRP使用的技术类似于距离向量协议:
• 路由器只用直接连接的邻居提供的信息作出路由决策;
• 路由器只向直接连接的邻居提供它所使用的路由信息。
但是,BEIGRP与距离向量有一些主要差别,使它具有更多优点:
• BEIGRP保存拓扑表中所有邻居发来的所有路由,而不只是保存迄今为止收到的最佳路由。
• BEIGRP在无法访问目的地而又没有替换路由时能对邻居进行查询,因此BEIGRP的收敛速度可以和最佳链路状态协议相媲美。
DUAL(Diffused Update Algorithm)即扩散更新算法的提出是BEIGRP优于其他传统的距离向量路由协议的关键所在。它总是非常积极的工作,在无法访问目的地而又没有替换路由(可行后续者)时能对邻居进行查询。由于汇总过程是主动的而不是被动的(被动的等待路由超时),因此BEIGRP的汇合速度很快。
BEIGRP是为了适应EIGRP的要求而设计的专有传输协议,直接建立在IP之上。它满足了BEIGRP的如下要求:
• 通过Hello报文动态的发现新邻居及旧邻居的消失;
• 所以数据传输均可靠;
• 传输协议允许单目广播和多目广播数据传输;
• 传输协议本身可以适应网络条件变化和邻居响应性变化;
• BEIGRP可以根据要求限制自己占用带宽的比率
要完成BEIGRP的配置需要完成下面的任务,其中激活BEIGRP协议是必须进行的,其他任务可以根据需要决定是否进行。
• 激活BEIGRP协议
• 配置占用带宽的百分比w
• 调整BEIGRP复合距离的计算系数
• 应用offset调整路由的复合距离
• 关闭路由汇总
• 定制路由汇总
• 配置转发路由
• 配置BEIGRP其他参数
• 监视与维护BEIGRP的运行
要创建一个BEIGRP进程,需要依次执行下列命令:
|
命令 |
目的 |
|
router beigrp as-number |
在全局配置态下增加一个BEIGRP进程。 |
|
Network network-number network-mask |
在路由配置态下增加网段到这个BEIGRP进程中。 |
完成上面的配置后,BEIGRP将开始在属于此网段的所有接口上运行。通过Hello发现新邻居,通过Update进行初始路由交互。
在缺省状态下,BEIGRP分组最多使用线路带宽的50%。你可能希望改变这个缺省值,以保证其他数据的正常交互,或者接口使用bandwidth命令配置了与实际不符的端口带宽,希望通过命令来调整BEIGRP真正可使用的带宽。在这些情况下,你可以在VLAN接口配置态中使用下面的命令:
|
命令 |
目的 |
|
ip beigrp bandwidth-percent percent |
配置BEIGRP报文使用的带宽占总带宽的最大百分比。 |
在某些情况下,可能需要调整BEIGRP复合距离的计算系数,从而最终影响路由的选路策略。虽然BEIGRP使用的缺省计算系数已经可以满足大多数网络环境,但在某些特殊条件下仍需要对其进行调整。但是这个调整可能会使整个网络产生巨大的变化,所有一定要由有丰富经验的工程师负责实施。
在路由配置态下使用下面的命令即可:
|
命令 |
目的 |
|
metric weights k1 k2 k3 k4 k5 |
调整BEIGRP复合距离计算系数。 |
我们使用偏移量列表可以根据需要有目的的增加所有入站和出站路由,或者其中符合要求的某几条路由的复合距离。这样作的目的是为了最终影响路由器的选路结果,已达到我们期望的结果。在配置过程中,可以根据你的需要有选择性的在偏移量列表中指定访问列表或应用接口,以进一步明确需要进行增加偏移量操作的路由。请看下面的命令:
|
命令 |
目的 |
|
offset{type number | *} {in | out} access-list-name offset |
应用一个偏移量列表 。 |
BEIGRP的自动汇总与其他的动态路由协议有些区别,它遵循如下规则:
• 一个BEIGRP过程定义多个网络时,只要该网络至少有一个子网在BEIGRP拓扑表中,就生成所定义网络的汇总路由。
• 建立的这条汇总路由指向Null0接口,具有汇总路由包括的网络中,所有子网的最小距离。汇总路由还插入主IP路由表中,管理距离为5(不可配置);
• 向不同主IP网络中的邻居发送更新时,规则1和规则2汇总的子网取消,只发送汇总路由;
• 不属于BEIGRP过程定义中列出的任何网络的子网不进行汇总。
在某些网络情况下,您可能希望将每一条具体的路由都通知给邻居,那么这时就可以使用下面的命令:
|
命令 |
目的 |
|
no auto-summary |
关闭路由自动汇总。 |
当路由自动汇总不能满足需求时,可以在每个运行BEIGRP的接口上配置路由汇总,指定希望进行汇总的目的网段。配置汇总的接口将不再发送属于此汇总网段子网的任何具体路由的更新信息,其他的接口不受影响。
此时的汇总操作遵循以下规则:
• 一个接口配置了汇总命令后,只要该网络至少有一个子网在BEIGRP拓扑表中,就生成所定义网络的汇总路由;
• 汇总路由指向Null0接口,具有汇总路由包括的所有具体路由的最小距离。汇总路由还插入到主IP路由表中,管理距离为5(不可配置);
• 在配置汇总范围的接口上发送路由更新时,取消属于汇总网段的具体路由。发送到其他接口的更新不受影响。
|
命令 |
目的 |
|
ip beigrp summary-address ip address address mask |
配置接口路由汇总。 |
BEIGRP转发其他类型路由时,它遵循如下规则:
• 如果预转发的路由是静态路由或者直连路由,不需要配置“default-metric”命令,其复合距离相关参数(带宽、延迟、可靠性、有效负载和MTU)直接从所在端口获得;
• 如果预转发的路由是BEIGRP协议的其他进程的路由,不需要配置“default-metric”命令,其复合距离相关参数直接从BEIGRP所在进程获得;
• 转发其他协议(如:rip,ospf)的路由,必须配置“default-metric”命令,其转发路由的符合距离由“default-metric”命令的配置值确定,若未曾配置“default-metric”命令则转发不起作用。
在同时运行BEIGRP协议和RIP协议的路由交换机上,如果希望BEIGRP邻居能够学习到本路由交换机中rip协议学习的路由,那么就必须使用以下命令:
|
命令 |
目的 |
|
default-metric bandwidth delay reliability loading mtu |
配置转发路由的缺省向量距离。 |
|
redistribute protocol [route-map name] |
进行转发路由至BEIGRP协议。 |
为了适应不同的网络环境,使BEIGRP能够更有效,更充分的发挥作用,我们可能还需要对下面的一些参数进行调整:
• 调整BEIGRP发送hello报文的时间间隔以及邻居超时死亡时间
• 关闭水平分割
5.3.8.1 调整BEIGRP发送hello报文的时间间隔以及邻居超时死亡时间
BEIGRP hello协议实现正确的BEIGRP操作所需的三个目标:
• 它发现能够访问的新邻居。邻居发现是自动的,不需要其他手工配置;
• 它验证邻居配置并只允许与以兼容方式配置的邻居通信;
• 它持续监视邻居可用性并探测邻居的消失。
路由器在运行BEIGRP的所有接口上发送hello多目广播分组。每个支持BEIGRP的路由器都接收这些多目广播分组,因此可以发现所有邻居。
Hello协议用两个定时器探测邻居的消失:hello间隔(hello interval)指定路由器的接口上发送BEIGRP hello报文的频度,而保持定时器(hold timer)指定路由器从指定邻居接收不到通信数据时等待多长时间再声明该邻居死亡。我们规定每次从相邻路由器收到任意类型的BEIGRP分组时都要复位保持定时器。
不同的网络类型或网络带宽将使用不同的hello定时器缺省值:
|
接口类型包装 |
|
Hello定时器(秒) |
保持定时器(秒) |
|
LAN接口 |
任意 |
5 |
15 |
Hello协议中定时器缺省值的不同可能导致连接相同IP子网的BEIGRP邻居使用不同的hello和保持定时器。要解决这个问题,每个路由器的hello分组中指定自己的保持定时器,每个BEIGRP路由器用邻居的hello分组中指定的保持定时器判断这个邻居的超时。这样就可以使不同邻居故障探测定时器可以出现在同一个WAN云图的不同站点中。但是在一些特殊情况下,定时器的缺省值并不能满足,所以如果希望调整发送hello报文的时间间隔,使用下面的命令:
|
命令 |
目的 |
|
ip beigrp hello-interval seconds |
调整发送此接口上发送hello报文的时间间隔。 |
|
|
|
如果希望调整邻居的超时定时器,使用下面的命令:
|
命令 |
目的 |
|
ip beigrp hold-time seconds |
调整邻居的超时死亡时间。 |
5.3.8.2关闭水平分割
一般情况下,我们希望使用水平分割。它将阻止从一个接口收到的路由信息再从同一个接口广播出去,从而避免路由循环。但在某些情况下,这样做并不是最优选择,那么我们可以使用下面的命令关闭水平分割:
|
命令 |
目的 |
|
no ip beigrp split-horizon |
关闭水平分割。 |
要清除与所有邻居的相邻性,使用下面的命令:
|
命令 |
目的 |
|
clear ip beigrp neighbors [ interface ] |
清除邻居的相邻性。 |
使用下面的命令可以显示BEIGRP的各种统计信息:
|
命令 |
目的 |
|
show ip beigrp interface [interface] [as-number] |
显示BEIGRP的接口信息。 |
|
show ip beigrp neighbors [as-number | interface] |
显示BEIGRP的邻居信息。 |
|
show ip beigrp topology [as-number | all-link | summary | active] |
显示BEIGRP的拓扑表信息。 |
下面的实例配置了在vlan1上发送10.0.0.0/8网段的汇总路由,属于此网段的所有子网路由将不会从此接口通知给邻居。同时,我们关闭了BEIGRP进程的自动汇总。
interface vlan 1
ip beigrp summary-address 10.0.0.0 255.0.0.0
!
router beigrp 1
network 172.16.0.0 255.255.0.0
no auto-summary
这一章介绍OSPF的配置。为了更详细了解OSPF的全部命令,请参考网络协议配置参考中的有关OSPF命令的相关章节。
OSPF是IETF的OSPF工作组的开发的IGP路由协议。 为IP网络设计的OSPF支持IP子网和外部路由信息标记,也允许报文的认证以及支持IP多播。
本公司路由交换机OSPF功能的实现遵守OSPF V2的要求(参见 RFC2328)。下面列出了实现中的一些关键特征:
|
关键特征 |
关键特征描述 |
|
Stub 域 |
支持stub域 |
|
路由转发 |
即被任何一种路由协议学习生成的路由都可以被转发到其他路由协议域。在自治域内,这表示OSPF能输入RIP学习到的路由。OSPF学习到的路由也可以输出到RIP。在自治域间,OSPF能输入 BGP学习到的路由; OSPF路由也能输出到BGP中去。 |
|
认证 |
在一个域内的邻接路由交换机之间,支持明文与MD5认证。 |
|
路由接口参数 |
可配置的接口参数有:输出花费、重传间隔、接口传输时延、路由交换机的优先级别、判定路由交换机的关机的时间间隔与hello包的时间间隔以及认证密钥。 |
|
虚链路 |
支持虚链路 |
|
NSSA 区 |
参见RFC 1587 |
|
按需电路上的OSPF |
RFC 1793 |
OSPF要求在全部域内路由交换机、ABR与ASBR之间进行交换路由数据。为了简化配置,可以让它们全部工作在默认参数,不需认证等;但如果要修改某些参数,则必须保证在所有路由交换机上的参数一致。
为了能配置OSPF, 完成下面的任务。除了激活 OSPF是必须的外,其他配置都是可选配置。
• 启动OSPF;
• 配置OSPF 的接口参数;
• 在不同的物理网络上的OSPF配置;
• 配置OSPF 域参数;
• 配置OSPF的NSSA域
• 配置OSPF域内路由的汇总
• 配置转发路由的汇总
• 生成默认路由
• 在LOOPBACK接口上选择路由ID
• 配置OSPF 的管理距离
• 配置路由计算的计时器
• 监视和维护OSPF
另外,配置路由转发, 可以参见配置独立协议的IP路由协议的特性配置的转发路由信息的有关内容。
与其他的路由协议一样,激活OSPF要求创建OSPF路由进程,要求分配一个与处理过程相关的IP地址范围,分配一个与IP地址范围相关的区域ID。在全局配置模式下,使用下面的命令:
|
命令 |
目的 |
|
router ospf process-id |
这个命令激活OSPF路由协议,并且进入路由交换机配置模式。 |
|
network address mask area area-id |
这个命令配置OSPF 运行的接口以及接口的区域ID。 |
在OSPF 实现中,允许按照需要修改接口有关的OSPF参数。并不需要改变任何一个参数,但必须保证某些参数在相连网络的所有路由交换机上的保持一致。
在接口配置模式,使用下面的命令配置接口参数:
|
命令 |
目的 |
|
ip ospf cost cost |
配置OSPF 接口发送包的权值。 |
|
ip ospf retransmit-interval seconds |
属于同一个OSPF接口的邻居之间重传LSA的秒数。 |
|
ip ospf transmit-delay seconds |
配置在一个OSPF接口传输LSA的估计时间(秒为单位)。 |
|
ip ospf priority number |
配置路由交换机成为OSPF DR路由交换机的优先值。 |
|
ip ospf hello-interval seconds |
配置在OSPF接口发送hello 包的时间间隔。 |
|
ip ospf dead-interval seconds |
在这个规定的时间间隔内,未收到邻居的hello包,则认为邻居路由交换机已关机。 |
|
ip ospf password key |
为一个网段内的邻接路由的认证口令。它使用OSPF的简单的口令认证。 |
|
ip ospf message-digest-key keyid md5 key |
要求OSPF 使用MD5 认证。 |
|
ip ospf passive |
在端口上不发送HELLO报文。 |
OSPF把网络的物理媒体,分成以下三类:
• 广播网络(Ethernet, Token Ring, FDDI)
• 非广播、多访问网络 (SMDS, Frame Relay, X.25)
• 点对点网络 (HDLC, PPP)
能配置你的网络或者广播网络或者是非广播、多访问网络。
X.25和帧中继网络提供了可选的广播能力,能通过map命令配置OSPF工作在广播网络。Map命令可以参见广域网命令参考中有关x.25与帧中继的map命令的描述。
不管网络的物理媒体类型,你都可以配置你的网络或者为广播网或者非广播、多访问网络。使用这个特性,你能灵活配置网络,可以将物理上的广播网络配置成非广播、多访问网络;也能配置非广播网络(X.25, Frame Relay, 与SMDS)成为广播网络。这个特征也减少对邻居的配置,具体参见为非广播网络配置OSPF相关内容。
配置非广播、多访问网络为广播网络或者非广播网络,即假设从每一个路由交换机到其他路由交换机都存在虚链路,或假设为一个全网状网络。由于花费的限制,这常常是不现实的;或者有一个部分网状网。这种情形下,你可以配置成点到多点网络。不相邻的路由交换机之间可以通过虚链路交换路由信息。
OSPF 点到多点接口可以定义成多个点到点网络接口,它建立多个主机路由。OSPF点到多点网络与非广播、多访问网络以及点到点网络相比,有以下优点:
• 点到多点网络容易配置,它不要求邻居配置命令,且不需产生DR
• 因为它不要求全网状拓扑,所以它的开销更小。
• 它更加可靠。即使在虚连路失败的情形下,也能保持连接。
在接口配置模式下,用下面的命令配置OSPF的网络类型。
|
命令 |
目的 |
|
ip ospf network {broadcast | non-broadcast | point-to-multipoint | point-to-point } |
这个命令配置OSPF的网络类型。 |
交换机的默认网络类型是广播类型。
可以配置的区域参数有:认证、指定Stub区、为默认汇总路由指定权值。认证采用基于口令保护。
Stub 区域即不分发外部路由到该区的区域。取而代之的是,在ABR生成一条默认外部路由进入stub区域,使它能到达自治区域的外部网络。为了利用OSPF Stub支持的特性,在Stub区域必须使用默认路由,为了进一步减少发送进入Stub区域的LSA数,你能在ABR禁止汇总(No Summary)来减少发送汇总LSA(类型3)进入Stub区域。
在路由配置模式,使用下面的命令设定区域参数:
|
命令 |
目的 |
|
area area-id authentication simple |
激活OSPF区域认证。 |
|
area area-id authentication message-digest |
使OSPF使用 MD5进行认证。 |
|
area area-id stub [no-summary] |
定义一个stub区。 |
|
area area-id default-cost cost |
为Stub区域的默认路由设定权值。 |
这个特性使得ABR广播一条汇总路由到其他区域。在OSPF中,ABR将广播每一个网络到其他区域。如果网络号按照某种方式分配,使得它们连续,你能配置ABR广播一条汇总路由到其他区。汇总路由能覆盖一定范围的所有网络。
在路由配置模式,使用下面的命令设定地址范围:
|
命令 |
目的 |
|
area area-id range address mask |
设定汇总路由的地址范围。 |
当从其他路由区域分发路由到OSPF路由区域时,每条路由以外部LSA的方式进行单独广播。然而你能配置路由交换机广播一条路由,它能覆盖一定的地址范围。这种方式可以减少OSPF链路状态数据库的大小。
在路由配置模式,使用下面的命令,配置汇总路由:
|
命令 |
目的 |
|
summary-address prefix mask [not advertise] |
描述覆盖分发路由的地址与掩码,仅仅一条汇总路由被广播。 |
能要求ASBR生成一条默认路由进入OSPF路由域。无论何时,你配置路由交换机分发路由进入OSPF路由域,该路由自动变成ASBR。然而,ASBR默认并不生成默认路由进入OSPF路由域。
在路由配置模式,使用下面的命令,强制ASBR生成默认路由:
|
命令 |
目的 |
|
default-information originate [always] [route-map map-name| metric | metric-type| (cr)] |
强制ASBR生成默认路由进入OSPF路由域。 |
OSPF使用配置在接口的最大IP地址作为它的路由交换机ID。如果与这个IP地址相连的接口变为DOWN状态,或者该IP地址被删除,OSPF进程将重新计算新的路由交换机ID并且重新从所有接口发送路由信息。
如果一个loopback 接口配置了IP地址,则路由交换机使用IP地址作为它的路由交换机ID,由于loopback接口永远不会Down,所有使得路由表具有较大的稳定性。
路由交换机优先选用Loopback接口作为路由交换机ID,同时也选择所有Loopback接口中最大的IP地址作为路由交换机ID。如果没有Loopback接口,则使用路由交换机的最大IP地址。你不能指定OSPF使用任何特定的接口。
在全局模式下,使用下面的命令,配置IP Loopback接口。
|
命令 |
目的 |
|
interface loopback 0 |
创建一个loopback接口且进入接口配置模式。 |
|
ip address ip-address mask |
为接口分配一个IP 地址。 |
管理距离是路由信息源的信任等级,如单个路由交换机或一组路由交换机。一般来说,管理距离是0-255之间的整数,值越大,信任级别越低。如果管理距离为255,则路由信息源不被信任且应当被忽略。
OSPF使用三类不同的管理距离:域间、域内和外部。在一个区域内的路由是域内;到其他区域的路由是区域间;其他路由协议域分发来的路由为外部。每种类型路由的默认值为110。
在路由配置模式下,使用下面的命令,配置OSPF的距离值:
|
命令 |
目的 |
|
distance ospf [intra-area dist1] [inter-area dist2] [external dist3] |
改变OSPF 域内、域间以及外部路由管理距离值。 |
你能配置OSPF收到拓扑变化消息与开始计算SPF之间的时延。也能配置连续两次计算SPF之间的间隔。在路由配置模式,使用下面的命令进行配置:
|
命令 |
目的 |
|
timers delay-timer delaytime |
设定在一个域中路由计算的时间延迟。 |
|
timers hold-timer holdtime |
设定在一个域中路由计算的最小时间间隔。 |
平滑重启(Graceful Restart,简称GR)属于高可靠性(High Availability,简称HA)技术的一种,表示当主备切换或路由协议重启时,能保证数据的正常转发,从而保证关键业务不中断。
配置GR Restarter。使能IETF标准的平滑重启能力(基于rfc 3623),在路由配置模式,使用下面的命令进行配置:
|
命令 |
目的 |
|
graceful-restart interval period |
使能IETF标准的平滑重启能力(基于rfc 3623)。并配置平滑重启的时间上限,取值范围40~1800s,默认取值120s,建议至少40s。 |
配置GR Helper。缺省情况下,设备可以作任一OSPF邻居的GR Helper,若要关闭GR Helper能力,在路由配置模式,使用下面的命令进行配置:
|
命令 |
目的 |
|
graceful-restart ietf helper disable |
关闭GR Helper能力 |
在GR Helper端。缺省情况下,关闭strict-lsa-checking能力,若要开启该能力,当GR Helper检测到有LSA发生变化时,退出Help Mode,在路由配置模式,使用下面的命令进行配置:
|
命令 |
目的 |
|
graceful-restart ietf helper strict-lsa-checking |
开启strict-lsa-checking能力 |
若要平滑重启OSPF进程,以IETF标准方式实现时,要求这些设备上必须预先具备以下两种
能力:Opaque LSA 发布能力和 IETF标准的GR能力,前者在路由器中默认开启,无
需配置,后者请按上述操作执行。具备以上两种能力后,在管理态下,使用下面的命令进行路由协议重启配置:
|
命令 |
目的 |
|
restart ospf [process-id] graceful |
重启OSPF协议 |
或者当设备发生主备倒换时,自动平滑重启OSPF进程。
能显示网络的统计信息,如:IP路由表的内容、缓冲和数据库等数据。这些信息能帮助你判断网络资源的利用,解决网络问题。能了解网络节点的可达性,发现网络数据包经过网络的路由。
使用下面的命令,可以显示各种路由统计信息:
|
命令 |
目的 |
|
show ip ospf [process-id] |
显示OSPF 路由进程的一般信息。 |
|
show ip ospf [process-id] database show ip ospf [process-id] database [router] [link-state-id] show ip ospf [process-id] database [router] [self-originate] show ip ospf [process-id] database [router] [adv-router [ip-address]] show ip ospf [process-id] database [network] [link-state-id] show ip ospf [process-id] database [summary] [link-state-id] show ip ospf [process-id] database [asbr-summary] [link-state-id] show ip ospf [process-id] database [external] [link-state-id] show ip ospf [process-id] database [database-summary] |
显示OSPF数据库的相关信息。 |
|
show ip ospf border-routers |
显示ABR与ASBR的内部路由表项。 |
|
show ip ospf interface |
显示有关OSPF接口的信息。 |
|
show ip ospf neighbor |
按照接口,显示OSPF的邻居信息。 |
|
debug ip ospf adj |
监视OSPF的邻接建立过程。 |
|
debug ip ospf events |
监视OSPF的接口和邻居事件。 |
|
debug ip ospf flood |
监视OSPF的数据库的扩散过程。 |
|
debug ip ospf lsa-generation |
监视OSPF的LSA的生成过程。 |
|
debug ip ospf packet |
监视OSPF的报文。 |
|
debug ip ospf restart |
监视OSPF的平滑重启过程。 |
|
debug ip ospf retransmission |
监视OSPF的报文重发过程。 |
|
debug ip ospf spf debug ip ospf spf intra debug ip spf inter debug ip ospf spf external |
监视OSPF的SPF计算路由。 |
|
debug ip ospf tree |
监视OSPF的SPF树的建立。 |
OSPF、静态路由支持可变长子网掩码(VLSMs). 通过VLSMs, 能在不同的接口对于同一网络号码使用不同的掩码,这节约了IP地址,更加有效利用网络的地址空间。
在下面的例子中,使用了30位的子网掩码,保留两位地址空间作为串行口的主机地址。这对于点到点的串行链路仅仅只需两个主机地址,已经足够了。
interface vlan 10
ip address 131.107.1.1 255.255.255.0
! 8 bits of host address space reserved for ethernets
interface vlan 11
ip address 131.107.254.1 255.255.255.252
! 2 bits of address space reserved for serial lines
! Router is configured for OSPF and assigned AS 107
router ospf 107
! Specifies network directly connected to the router
network 131.107.0.0 0.0.255.255 area 0.0.0.0
OSPF要求在众多内部路由交换机、ABR与ASBR间交换信息。在最小配置下,基于OSPF的路由交换机可以在默认参数下工作,没有认证要求。
下面是三个配置例子:
第一个例子练习基本OSPF命令。
第二个例子练习配置内部路由交换机、ABR 与ASBR在单一OSPF自治系统内的配置。
第三个例子说明了一个更加复杂的利用OSPF的各种工具的配置例子。
6.4.2.1基本OSPF 配置例子
下面的例子说明一个简单的OSPF配置。激活路由进程90,连接以太口0到区域0.0.0.0。同时分发RIP到OSPF,OSPF到RIP。
interface vlan 10
ip address 130.130.1.1 255.255.255.0
ip ospf cost 1
!
interface vlan 10
ip address 130.130.1.1 255.255.255.0
ip rip 1 enable
!
router ospf 90
network 130.130.0.0 255.255.0.0 area 0
redistribute rip
!
router rip 1
redistribute ospf 90
6.4.2.2配置内部路由交换机、ABR与ASBR的基本配置例子
下面的例子为四个IP地址范围分配了四个区域ID。首先路由进程109被激活,四个区域为:10.9.50.0, 2, 3, 与 0。区域10.9.50.0, 2, 与3 的掩码指定了地址范围,而区域0包含所有的网络。
router ospf 109
network 131.108.20.0 255.255.255.0 area 10.9.50.0
network 131.108.0.0 255.255.0.0 area 2
network 131.109.10.0 255.255.255.0 area 3
network 0.0.0.0 0.0.0.0 area 0
!
! Interface vlan10 is in area 10.9.50.0:
interface vlan 10
ip address 131.108.20.5 255.255.255.0
!
! Interface vlan11 is in area 2:
interface vlan 11
ip address 131.108.1.5 255.255.255.0
!
! Interface vlan12 is in area 2:
interface vlan 12
ip address 131.108.2.5 255.255.255.0
!
! Interface vlan13 is in area 3:
interface vlan 13
ip address 131.109.10.5 255.255.255.0
!
! Interface vlan14 is in area 0:
interface vlan 14
ip address 131.109.1.1 255.255.255.0
!
! Interface vlan 100 is in area 0:
interface vlan 100
ip address 10.1.0.1 255.255.0.0
网络区域配置命令作用是有顺序的,所以命令的顺序是重要的。路由交换机是按顺序匹配每个接口的地址/掩码对。具体可以参见“OSPF 命令”中有关网络协议命令参考中的相关内容。
可以看看第一个网络区域。即区域ID 10.9.50.0配置的接口子网为131.108.20.0。则以太接口0匹配。则接口0仅在区域10.9.50.0。
接下来第二个区域。除了接口0,同样的过程分析其他接口,则以太口1匹配。所以接口1连接到区域2。
继续匹配其他的网络区域。注意最后一个网络区域命令是一个特例,它表示剩下的接口都连接到网络区域0。
6.4.2.3复杂的内部路由交换机、ABR、ASBR的配置例子
下面的例子演示了在单个OSPF自治系统内,多个路由交换机的配置。下图是配置例子的网络拓扑图。
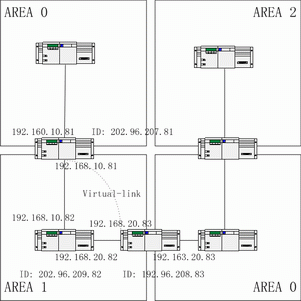
按照上图配置路由交换机。
RTA:
interface loopback 0
ip address 202.96.207.81 255.255.255.0
!
interface vlan 10
ip address 192.168.10.81 255.255.255.0
!
interface vlan 10
ip address 192.160.10.81 255.255.255.0
!
router ospf 192
network 192.168.10.0 255.255.255.0 area 1
network 192.160.10.0 255.255.255.0 area 0
!
RTB:
interface loopback 0
ip address 202.96.209.82 255.255.255.252
!
interface vlan 10
ip address 192.168.10.82 255.255.255.0
!
interface vlan 11
ip address 192.160.20.82 255.255.255.0
!
router ospf 192
network 192.168.20.0 255.255.255.0 area 1
network 192.168.10.0 255.255.255.0 area 1
!
RTC:
interface loopback 0
ip address 202.96.208.83 255.255.255.252
!
interface vlan 10
ip address 192.163.20.83 255.255.255.0
!
interface vlan 11
ip address 192.160.20.83 255.255.255.0
!
router ospf 192
network 192.168.20.0 255.255.255.0 area 1
network 192.163.20.0 255.255.255.0 area 0
!
下面例子说明了配置ABR涉及的几个任务。可以分成以下两个目录:
• 基本OSPF配置;
• 路由分发;
在这个配置中的任务下面作了简单的描述。下图说明了网络地址的范围与区域的分配。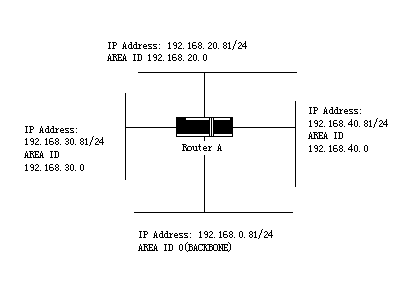
这个例子的基本配置任务如下:
(1)为以太口0到3配置地址范围。
(2)激活OSPF 在每一个接口。
(3)为每个区域和网络设置OSPF认证口令。
(4)设定链路状态权值和其他接口参数。
在创建Stub区36.0.0.0。
注意:对于认证与Stub区域参数的设定,分别使用一条area 命令。也可以用一条命令来设定这些参数。
• 设定骨干区域 (Area 0).
与分发相连的配置任务如下:
• 分发IGRP与RIP路由进入OSPF的参数设置(包括metric-type, metric, tag, 与 subnet)。
• 分发IGRP 与OSPF 的路由进入RIP.
下面是OSPF配置例子:
interface vlan 10
ip address 192.168.20.81 255.255.255.0
ip ospf password GHGHGHG
ip ospf cost 10
!
interface vlan 11
ip address 192.168.30.81 255.255.255.0
ip ospf password ijklmnop
ip ospf cost 20
ip ospf retransmit-interval 10
ip ospf transmit-delay 2
ip ospf priority 4
!
interface vlan 12
ip address 192.168.40.81 255.255.255.0
ip ospf password abcdefgh
ip ospf cost 10
!
interface vlan 13
ip address 192.168.0.81 255.255.255.0
ip ospf password ijklmnop
ip ospf cost 20
ip ospf dead-interval 80
!
router ospf 192
network 192.168.0.0 255.255.255.0 area 0
network 192.168.20.0 255.255.255.0 area 192.168.20.0
network 192.168.30.0 255.255.255.0 area 192.168.30.0
network 192.168.40.0 255.255.255.0 area 192.168.40.0
area 0 authentication simple
area 192.168.20.0 stub
area 192.168.20.0 authentication simple
area 192.168.20.0 default-cost 20
area 192.168.20.0 authentication simple
area 192.168.20.0 range 36.0.0.0 255.0.0.0
area 192.168.30.0 range 192.42.110.0 255.255.255.0
area 0 range 130.0.0.0 255.0.0.0
area 0 range 141.0.0.0 255.0.0.0
redistribute rip 1
RIP在网络192.168.30.0。
router rip 1
redistribute ospf 192
!
Inter v11
ip rip 1 enable
BFD(Bidirectional Forwarding Detection,双向转发检测)是一套全网统一的检测机制,用于快速检测、监控网络中链路或者IP 路由转发的连通状况。为了提升现有网络性能,相邻协议之间必须能快速检测到通信故障,从而更快的建立起备用通道恢复通信。
BFD 在两台路由器(交换机)上建立会话,用来监测两台路由器(交换机)间的双向转发路径,为上层协议服务。需要服务的上层协议通知其该与谁建立会话,通过3次握手会话建立后如果在检测时间内没有收到对端的BFD 控制报文或回声报文丢失报文的数量超过配置允许的最大值则认为发生故障,通知被服务的上层协议,上层协议进行相应的处理。
缺省情况下,接口bfd功能未激活。
在使能接口bfd功能后,各动态协议配置的bfd检测功能才能生效。
使用下面的BFD配置命令来达到上述目的:
|
命令 |
目的 |
|
bfd enable <cr> | {min_tx_interval <tx_value> min_rx_interval <rx_value> multi <m_value> |
激活接口bfd功能。 |
BFD会话建立前BFD控制报文以不小于1秒的时间间隔周期发送以减小报文流量。在会话建立后则以协商的时间间隔发送BFD控制报文以实现快速检测。在BFD会话建立的同时,BFD控制报文发送时间间隔以及检测时间也会通过报文交互协商确定。在BFD会话有效期间,这些定时器可以随时协商修改而不影响会话状态。BFD会话不同方向的定时器协商是分别独立进行的,双向定时器时间可以不同。BFD控制报文发送时间间隔为本端min_tx_interval与对端min_rx_interval之中的最大值,也就是说比较慢的一方决定了发送频率。
检测时间为对端BFD控制报文中的Detect Mult(即对端配置的检测系数)乘以经过协商的对端BFD控制报文发送时间间隔。如果加大本端min_tx_interval,那么本端实际发送BFD控制报文的时间间隔必须要等收到对端F字段置位的报文后才能改变,这是为了确保在本端加大BFD控制报文发送时间间隔前对端已经加大了检测时间,否则可能导致对端检测定时器错误超时。
如果减小本端min_rx_interval,那么本端检测时间必须要等收到对端F字段置位的报文后才能改变,这是为了确保在本端减小检测时间前对端已经减小了BFD控制报文发送间隔时间,否则可能导致本端检测定时器错误超时。然而如果减小min_tx_interval,本端BFD控制报文发送时间间隔将会立即减小;加大min_rx_interval,本端检测时间将会立即加大。
缺省情况下,接口bfd echo功能未激活。
bfd echo(回声)功能激活后,支持bfd echo功能的邻居up以后控制报文按照slow-timers配置的时间间隔发送,连通性检测功能由回声报文完成,回声报文发送时间间隔为 bfd min_echo_rx_interval 命令配置的时间。
使用下面的BFD配置命令来达到上述目的:
|
命令 |
目的 |
|
bfd echo enable <cr>|<number> |
激活bfd echo(回声)功能。 |
已经up的邻居echo功能的激活和关闭不影响其状态,只影响到控制报文发包的时间间隔(速率)。
使用下面的管理命令显示各种BFD统计信息:
|
命令 |
目的 |
|
show bfd interfaces details |
显示系统中的激活BFD功能接口列表 。 |
|
show bfd neighbors details |
显示系统中BFD邻居详细信息。 |
PBR是策略路由(Policy Based Routing)的英文缩写。PBR使得用户可以依靠某种策略来进行路由,而不是依赖路由协议。PBR目前支持的策略是:ip报文大小、源ip地址。用户可以为符合策略的报文指定下一跳ip address或者下一条端口。PBR支持负载均衡,对符合策略的报文可以应用多个下一跳ip地址或端口。
PBR应用下一跳的规则如下:
• 如果配置了set ip next-hop,并且nexthop是可到达的,则采用nexthop。如果有多个nexthop,则采用第一个可到达的nexthop,如果多个nexthop是load-balance方式,则轮流选择这些nexthop。
• 如果配置了set interface,并且interface处于可路由(端口协议up,配置了ip地址)状态,则采用该端口作为下一跳端口。如果有多个interface,则采用第一个可路由的端口,如果这些多个interface是load-balance方式,则轮流选择这些端口。如果同时配置set ip next-hop和set interface,优先选择set ip next-hop。
• set ip default next-hop或set default interface仅在基于目的ip地址的路由表查找失败的情况下有效。
对以下报文,不会应用策略路由:
• 对于目的地址是本地的报文。
• multicast报文
• 本地直连广播报文
如果想配置PBR,有以下任务需要完成。
• 创建访问列表(可选)
• 创建route-map
• 将route-map应用到端口
要创建访问列表,在全局配置模式下按以下步骤进行:
|
命令 |
说明 |
|
ip access-list standard net1 |
进入访问列表配置模式,定义访问列表。 |
要创建route-map,在全局配置模式下按以下步骤进行:
|
命令 |
说明 |
|
route-map pbr |
进入route-map配置模式。 |
|
match ip address access-list match length min_length max_length |
配置匹配策略。 |
|
set ip [default] next-hop A.B.C.D set [default] interface interface_name |
配置IP报文下一跳地址或端口。 |
按以下步骤在ip报文接收端口应用策略路由:
|
命令 |
说明 |
|
interface interface_name |
进入端口配置模式。 |
|
ip policy route-map route-map_name |
在端口应用策略路由。 |
维护PBR,在管理态下,按以下步骤进行:
|
命令 |
说明 |
|
debug ip policy |
查看应用策略路由的结果。 |
交换机配置:
!
interface Vlan1
ip address 10.1.1.3 255.255.255.0
no ip directed-broadcast
ip policy route-map pbr
!
interface Vlan2
ip address 13.1.1.3 255.255.255.0
no ip directed-broadcast
!
interface Vlan3
ip address 14.1.1.3 255.255.255.0
no ip directed-broadcast
!
ip access-list standard net1
permit 10.1.1.2 255.255.255.255
!
ip access-list standard net2
permit 10.1.1.4 255.255.255.255
!
ip access-list standard net3
permit 10.1.1.21 255.255.255.255
!
route-map pbr 10 permit
match ip address net1
set ip next-hop 13.1.1.99
!
route-map pbr 20 permit
match ip address net2
set ip next-hop 14.1.1.99
!
route-map pbr 30 permit
match ip address net3
set ip next-hop 13.1.1.99 14.1.1.99 load-balance
!
route-map pbr 40 permit
set ip default next-hop 13.1.1.99
配置说明
交换机将对从vlan1收到的报文应用策略路由。对于源ip地址是10.1.1.2的报文,其下一跳是13.1.1.99,如果在路由表中有到下一跳13.1.1.99的路由,则应用该路由,如果在路由表中没有到13.1.1.99的路由,则采用根据目的ip地址查找路由表获得的路由。对于源ip地址是10.1.1.21的报文,将应用route-map pbr 30,由于set ip next-hop 带了load-balance 参数,下一跳轮流选择13.1.1.99、14.1.1.99 (假设路由表中有到13.1.1.99和14.1.1.99的路由 )。
在测试路由协议时,可以通过FP将路由协议报文送到CPU的优先级提高。这样可以在系统收到超负载的背景流量(例如需要转发的IP报文)时,保证路由协议报文能够收上来。
如果想提高路由协议报文送到CPU的优先级,需要完成下面的配置任务:
• 开启提高路由协议报文送到CPU的优先级功能
在全局配置模式下,进行如下配置:
|
命令 |
目的 |
|
switch routing-protocol-highpriority |
开启提高路由协议报文送到CPU的优先级功能。 |